[Kubernetes] MIG 적용하여 A100 GPU 쪼개기
1.NVIDIA Multi-Instance GPU
Nvidia, cuda 관련 toolkit, driver가 설치되어있다는 전제하에 진행했습니다!
SUDO 권한으로 진행하는 것을 권장합니다.

기존에는 nvidia-smi 결과가 위와같이 MIG mode가 Disabled 인것을 볼 수 있습니다.
MIG 를 적용하기 위해선, nvidia-smi -mig 1 명령어를 통해 적용할 수 있습니다.
특정 GPU 카드에만 적용하기 위해선 nvidia-smi -mig 1 -i {gpu id} 로 gpu id를 지정하여 enable이 가능합니다.

모든 gpu 카드에 적용했으나 위처럼 Enabled* 로 아래와 같은 오류가 발생한다면, 아직 사용 가능하지 않음을 의미합니다.
root@OP-L-APOLLO-GPU-007:/home # nvidia-smi -mig 1
Warning: MIG mode is in pending enable state for GPU 00000000:07:00.0:Timeout
Reboot the system or try nvidia-smi --gpu-reset to make MIG mode effective on GPU 00000000:07:00.0
Warning: MIG mode is in pending enable state for GPU 00000000:0B:00.0:Timeout
Reboot the system or try nvidia-smi --gpu-reset to make MIG mode effective on GPU 00000000:0B:00.0
Warning: MIG mode is in pending enable state for GPU 00000000:48:00.0:Timeout
Reboot the system or try nvidia-smi --gpu-reset to make MIG mode effective on GPU 00000000:48:00.0
Warning: MIG mode is in pending enable state for GPU 00000000:4C:00.0:Timeout
Reboot the system or try nvidia-smi --gpu-reset to make MIG mode effective on GPU 00000000:4C:00.0
Warning: MIG mode is in pending enable state for GPU 00000000:88:00.0:Timeout
Reboot the system or try nvidia-smi --gpu-reset to make MIG mode effective on GPU 00000000:88:00.0
Warning: MIG mode is in pending enable state for GPU 00000000:8B:00.0:Timeout
Reboot the system or try nvidia-smi --gpu-reset to make MIG mode effective on GPU 00000000:8B:00.0
Warning: MIG mode is in pending enable state for GPU 00000000:C8:00.0:Timeout
Reboot the system or try nvidia-smi --gpu-reset to make MIG mode effective on GPU 00000000:C8:00.0
Warning: MIG mode is in pending enable state for GPU 00000000:CB:00.0:Timeout
Reboot the system or try nvidia-smi --gpu-reset to make MIG mode effective on GPU 00000000:CB:00.0
All done.
Reboot는 최후의 수단으로 남겨놓고, 시도해보라는 nvidia-smi --gpu-reset 부터 진행했습니다.
하지만 아래와 같은 다른 프로세스들이 실행중이라는 이유로 리셋되지 않았습니다.
root@OP-L-APOLLO-GPU-007:/home # nvidia-smi --gpu-reset
The following GPUs could not be reset:
GPU 00000000:07:00.0: In use by another client
GPU 00000000:0B:00.0: In use by another client
GPU 00000000:48:00.0: In use by another client
GPU 00000000:4C:00.0: In use by another client
GPU 00000000:88:00.0: In use by another client
GPU 00000000:8B:00.0: In use by another client
GPU 00000000:C8:00.0: In use by another client
GPU 00000000:CB:00.0: In use by another client
8 devices are currently being used by one or more other processes (e.g., Fabric Manager, CUDA application, graphics application such as an X server, or a monitoring application such as another instance of nvidia-smi). Please first kill all processes using these devices and all compute applications running in the system.
따라서, 저는 Document에 나와있는 방법대로 관련 프로세스들을 stop하는 방법으로 진행했지만 제대로 이뤄지지 않았습니다. (참조링크: https://docs.nvidia.com/datacenter/tesla/mig-user-guide/index.html#:~:text=is%20not%20supported.-,Driver%20Clients,-In%20some%20cases)
따라서, Reboot을 진행하기로 했습니다.
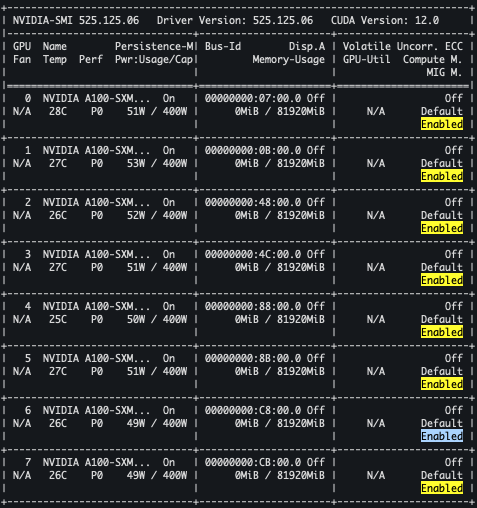
Reboot 이후엔 아래와 같이 정상적으로 Enable 되는 것을 확인할 수 있습니다.
그 다음으로, 구성 가능한 MIG를 얻기 위해 nvidia-smi mig -lgip 명령어를 통해 MIG profile을 확인합니다. (너무 많아서 캡쳐화면을 잘랐습니다.)
중요하게 봐야할 부분은 Instances부분인데, GPU 카드에 적용할 수 있는 해당 MIG의 총 갯수와 가능한 갯수를 의미합니다.

저는 8개의 GPU 카드를 4개는 15번 MIG를 각 4개씩, 나머지 4개의 카드는 9번 MIG를 2개씩 적용하는 방향으로 진행했습니다.
정상적으로 적용되면 아래와 같은 로그를 확인할 수 있습니다.
root@OP-L-APOLLO-GPU-007:/home# nvidia-smi mig -cgi 9,9 -C -i 0,1,2,3
Successfully created GPU instance ID 2 on GPU 0 using profile MIG 3g.40gb (ID 9)
Successfully created compute instance ID 0 on GPU 0 GPU instance ID 2 using profile MIG 3g.40gb (ID 2)
Successfully created GPU instance ID 1 on GPU 0 using profile MIG 3g.40gb (ID 9)
Successfully created compute instance ID 0 on GPU 0 GPU instance ID 1 using profile MIG 3g.40gb (ID 2)
…
root@OP-L-APOLLO-GPU-007:/home# nvidia-smi mig -cgi 15,15,15,15 -C -i 4,5,6,7
Successfully created GPU instance ID 6 on GPU 4 using profile MIG 1g.20gb (ID 15)
Successfully created compute instance ID 0 on GPU 4 GPU instance ID 6 using profile MIG 1g.20gb (ID 0)
Successfully created GPU instance ID 5 on GPU 4 using profile MIG 1g.20gb (ID 15)
Successfully created compute instance ID 0 on GPU 4 GPU instance ID 5 using profile MIG 1g.20gb (ID 0)
Successfully created GPU instance ID 3 on GPU 4 using profile MIG 1g.20gb (ID 15)
Successfully created compute instance ID 0 on GPU 4 GPU instance ID 3 using profile MIG 1g.20gb (ID 0)
Successfully created GPU instance ID 4 on GPU 4 using profile MIG 1g.20gb (ID 15)
Successfully created compute instance ID 0 on GPU 4 GPU instance ID 4 using profile MIG 1g.20gb (ID 0)
…
정상적으로 생성되었는지, 사용 가능한 인스턴스 목록을 확인합니다. ( MIG devices 확인 )
nvidia-smi
nvidia-smi -L
2.Kubernetes에서 MIG 인식하기 (아래의 버전을 만족해야 합니다.)
- NVIDIA R450+ datacenter driver: 450.80.02+
- NVIDIA Container Toolkit (nvidia-docker2): v2.5.0+
- NVIDIA k8s-device-plugin: v0.7.0+
- NVIDIA gpu-feature-discovery: v0.2.0+
nvidia-device-plugin 와 gpu-feature-discovery helm repository를 추가합니다.
$ helm repo add nvdp https://nvidia.github.io/k8s-device-plugin
$ helm repo add nvgfd https://nvidia.github.io/gpu-feature-discovery
$ helm repo update
repository의 버전을 확인합니다.
$ helm search repo nvdp --devel
$ helm search repo nvgfd --devel
MIG strategy를 선택하고 nvidia-device-plugin 및 gpu-feature-discovery 구성 요소를 배포합니다.
$ export MIG_STRATEGY=<none | single | mixed> # (none, single, mixed) 중 하나를 선택한다.
nvidia-device-plugin 과 gpu-featrue-discovery 를 각각 설치합니다.
$ helm install \
--version=0.7.0 \
--wait \
nvidia-device-plugin \
nvdp/nvidia-device-plugin \
--set migStrategy=${MIG_STRATEGY}
$ helm install \
--version=0.2.0 \
--wait \
gpu-featrue-discovery \
nvgfd/gpu-feature-discovery \
--set migStrategy=${MIG_STRATEGY}
...
Capacity:
nvidia.com/gpu: 1
...
Allocatable:
nvidia.com/gpu: 1
...
$ kubectl describe node 시 위와 같이 아직 nvidia.com/gpu로 나타나면 아래 처럼 나오도록 해줘야한다.
…
nvidia.com/gpu: 0
nvidia.com/mig-1g.20gb: 16
nvidia.com/mig-3g.40gb: 8
…
MIG가 적용되어있는 GPU 노드의 kubelet을 restart 해준다.
$ systemctl restart kubelet
마지막으로, 아래와 같이 결과가 나오면 끝
$ kubectl describe node
...
Capacity:
nvidia.com/mig-1g.5gb: 1
nvidia.com/mig-2g.10gb: 1
nvidia.com/mig-3g.20gb: 1
...
Allocatable:
nvidia.com/mig-1g.5gb: 1
nvidia.com/mig-2g.10gb: 1
nvidia.com/mig-3g.20gb: 1
...
추가로, MIG 가 잘 적용되었는지 Pod을 생성하는 예시입니다.
$ kubectl run -it --rm \
--image=nvidia/cuda:9.0-base \
--restart=Never \
--limits=nvidia.com/gpu=1 \
mig-none-example -- nvidia-smi -L